

In a groundbreaking move, the London Stock Exchange, one of the largest institutions of its kind globally, recently partnered with Microsoft to transition its data platform and other key technology infrastructure to Microsoft's Azure cloud. This decision reflects growing confidence in cloud technology within the financial sector and represents a significant shift in the industry. The partnership aims to leverage Azure's advanced networking capabilities and high-performance computing architecture, offering a low-latency, scalable, and resilient solution, marking a significant transformation in LSEG's data infrastructure approach.
Trading systems traditionally relied on large on-premise servers and networking infrastructure, leveraging physical proximity to achieve minimal transaction latency for real-time trading experiences. However, the tide is shifting as financial institutions increasingly acknowledge the advantages of cloud infrastructure. In addition to its impressive performance, Azure offers unmatched scalability and resiliency, making it an attractive choice for financial institutions looking to migrate their trading systems to the cloud. Furthermore, Azure's extensive range of cloud services, security offerings, and global data center footprint provide businesses with the necessary tools and infrastructure to build, deploy, and manage trading platforms at scale.
About BJSS
BJSS is a leading software consulting group with extensive experience designing and implementing low-latency trading systems for financial institutions. We have worked with some of the largest banks in the world and have built some of the most widely used trading platforms in the world today. As a technology leader in financial services, we set out to demonstrate the feasibility of hosting a low-latency trading system in the cloud. In 2018, we built a simple foreign exchange (FX) trading system and deployed it to a cloud environment, applying high performance tuning and robust controls for recording network latency and overall system latency. Our results were published by the IEEE in the 2019 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC).
Considering the recent surge of interest from financial institutions in adopting the use of cloud infrastructure, we decided to re-run our performance testing to see how Azure has progressed in its support of accelerated networking for low-latency trading.
We would like to thank Microsoft for their support and use of a trial subscription in concert with this effort. We understand that this research is of immense importance to industry leaders in cloud computing and we appreciate their partnership.
Systems Under Test
We designed our system under test according to a few guiding principles:
- Simple architecture: The system models a foreign-exchange immediate-or-cancel (IOC) transaction, isolating the network performance with minimal processing. The system is designed to be brokerless, reducing the number of points along the roundtrip transaction path.
- Industry standard: The system is written in Java, an industry-standard language for enterprise trading systems, using standard industry messaging patterns including the LMAX Disruptor pattern for publishing and consuming messages.
- Lowest latency: The system is designed to minimize network and process latency by applying various configurations to optimize networking performance and eliminate context switching and thread contention.
- Accurate measurement: The system is designed with measurement points that isolate network latency and process latency, and to accurately measure each, without impact to the performance of the main process thread. In addition, we eliminated the potential for clock skew to impact the measurements by measuring only timestamp differentials beginning and ending on the same host.
Resulting architecture:

Figure 1. System Architecture under Test
Our test system implements an Order Book and FX Matching Engine in an “immediate-or-cancel” trading scenario (see Figure 1). This includes an Order Generator sending orders to an Order Book, which saves the order and forwards it to a Matching Engine, which returns results to the Order Book. The rings represent the LMAX disrupter pattern used to optimize high-speed, low-latency message queuing between virtual machines.
The Order Generator (“OG”) exists to publish order messages to the Order Book (“OB”). This delegates the process time required to create an order away from the OB itself, allowing us to minimize process time measured and further reduce roundtrip latency measured.
Acting as an intermediary, the OB receives new order messages from the OG, decodes these messages, and stores them in memory. The OB also enriches the order message with receive and send timestamps before forwarding it on to the Matching Engine.
Once the Matching Engine (“ME”) receives the order, it immediately responds by returning the order with a “Cancel” status. This simulates the most common action on an FX exchange and is accomplished by duplicating the order message, setting its status to cancelled, timestamping it with the current time, and returning the message to the OB. Upon receiving this response, the OB removes the corresponding order from its records.
The system design assigns the responsibility of creating and publishing IOC order messages to the OG because orders in a high-volume order stream are typically created outside the OB. Therefore, the Total Latency measurement starts when the OB receives the message and ends when the OB processes the cancel sent by the ME. So, the latency measurements between OB and ME define our System Under Test.
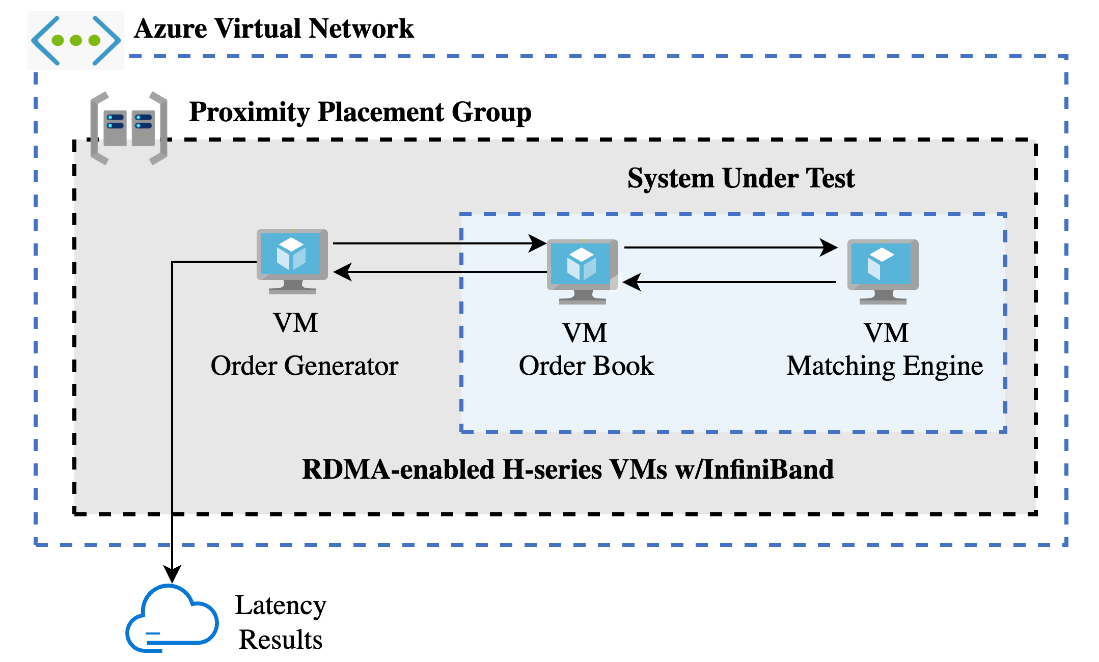
Figure 2. Azure Architecture Configuration
We applied specific configuration to support our latency goals at various levels:
Infrastructure
We selected the Azure Virtual Machine (VM) instance family and size that aligned with our requirements, placing a strong emphasis on achieving low-latency networking for efficient trade execution, while also ensuring the compute capacity to handle high trading volumes effectively. Our configuration included the utilization of Azure's RDMA-enabled Standard_HC44rs VMs, purpose-built for high-performance computing workloads, providing exceptional low-latency and high-throughput connections. To further optimize latency, we utilized Azure's Proximity Placement Groups, ensuring the VMs were in close physical proximity within the same data center (see Figure 2). Notably, one of the pivotal factors contributing to our low latency results was our use of InfiniBand, a high-speed, low-latency network protocol. InfiniBand's ability to directly access and transfer data from the application to the network interface helps bypass the software and hardware overheads associated with traditional Ethernet communications.
VM Configuration
The VM was equipped with CentOS Version 8.1. For optimal performance, we applied a low latency tuning profile, which included:
- Disabling hyperthreading.
- Shutting down unnecessary system processes.
- Running remaining system processes on isolated cores.
- Setting Ethernet thread affinity.
- Enabling busy polling and busy read for Ethernet.
- Enabling TCP fast open and low latency settings.
Network Configuration
We used the NVIDIA Mellanox ConnectX-5 Ex Network Interface Card, paired with the Mellanox OFED Linux 4.9-6.0.6.02 Driver and Mellanox Message Accelerator (VMA). These components facilitate high-speed, low-latency communication over an InfiniBand fabric. This allowed us to run standard TCP sockets on top of InfiniBand, providing compatibility with our Java application. Based on recommendations from NVIDIA's internal VMA team, which indicated that VMA support was removed in version 5.0 with the prospect of re-enablement in future iterations, we selected the Mellanox OFED Linux v4.9 driver. This driver offered the support for the VMA functionality we required, ensuring seamless integration with our network configuration.
Java Runtime
- Oracle JDK Version 19 which was the latest version of Java at the time of these tests and enabled us to test the latest garbage collector.
- Set CPU taskset to avoid conflict with system processes and optimize memory allocation with NUMA nodes to leverage L3 cache.
- Optimized garbage collection settings using the Z garbage collector (ZGC).
Test Load Parameters
In our recent study, we subjected the system to a range of tests with different loads, starting from 1,000 orders/second up to 50,000 orders/second on a single instance. These tests ran for a duration ranging from 30 minutes to 1 hour. We also performed a multi-instance test, where six products each generated 50,000 orders/second for 30 minutes, achieving a total throughput of 300,000 orders/second. Lastly, we performed a single 24-hour test at 10,000 orders/second.
Baseline Results
The tests demonstrated an improvement in latency measurements as the message rate increased. For instance, when we increased the message rate from 10,000 orders/second to 50,000 orders/second, the minimum, mean, 90th, and 99th percentile latency decreased. This is speculated to be due to VMA’s polling logic, which runs more efficiently at higher rates. These results underline the capacity of Azure's networking technology in delivering remarkable reductions in transaction latency, demonstrating its effectiveness over other cloud providers in the market.
At 50,000 orders/second, the average latency was measured at 8.76μs. The mean process time was 1.1μs and the mean network time was 7.6μs, showing that the bulk of the time was spent in the network communication stack rather than processing. We performed a multi-product test, where six products each generated 50,000 orders/second for 30 minutes, achieving a total of 300,000 orders/second (see Table 1).
|
Date |
2023-06-11 |
|
Instance Type |
Virtual |
|
Network |
InfiniBand |
|
Msg Rate/pair |
50,000 orders/sec |
|
Number of pairs |
6 |
|
Avg Latency |
9.34μs |
|
Total msg rate |
300,000 orders/sec |
|
90th % |
10.32μs |
|
99th % |
13μs |
|
Max Latency |
2.6ms |
Table 1: Standard HC44rs Stress Result
We also compared the same system under test performance when sending messages over TCP/Ethernet vs InfiniBand. Table 2 shows that at the 99th percentile level InfiniBand is 5.5 times faster than TCP/Ethernet. This improvement is due to several factors, but primarily due to bypassing JAVA’s Java Native Interface (JNI), kernel bypass via RDMA and InfiniBand’s cut-through network. The test system bypasses JNI by sending and receiving messages via the socket library. These sends and receives are trapped by the VMA library and sent over InfiniBand via the RDMA protocol.
|
Date |
2023-06-02 |
2023-06-27 |
|
Instance Type |
Virtual |
Virtual |
|
Network |
TCP/Ethernet |
InfiniBand |
|
Msg Rate |
10,000 orders/sec |
10,000 orders/sec |
|
Test Duration |
30 mins |
60 mins |
|
Avg Latency |
66.28μs |
9.06μs |
|
Min Latency |
58.3μs |
6.8μs |
|
90th % |
68.21μs |
9.9μs |
|
99th % |
71.41μs |
12.7μs |
|
Max Latency |
1.56ms |
960.74μ |
Table 2: TCP/Ethernet vs. InfiniBand
With Azure's advancements in networking and High-Performance Computing (HPC) architecture, particularly the effective use of RDMA-enabled network interfaces, we observed remarkable performance. During a 30-minute test, InfiniBand consistently maintained an average latency under 9-10 microseconds, with the 99th percentile latency falling below 13 microseconds. To put these results into context, a 99th percentile latency under 500 microseconds is typically deemed as acceptable performance for many types of asset class trading scenarios. Hence, Azure's capability to achieve latency in the sub-13 microsecond range demonstrates an exceptionally high level of performance that far surpasses this threshold.
Stress Test Summary and Findings
A rigorous stress test was conducted to ascertain the peak order rate our system could handle while maintaining deterministic latency at the 99th percentile level. Our results demonstrated that a single Order Book (OB)/Matching Engine (ME) pair could process 50,000 orders/second, achieving a 99th percentile latency of 12.7 microseconds. This was determined to be the upper limit for a single OB/ME pair.
To further stress the system, we ran multiple instances of the OB/ME pairs concurrently on the same VMs. At an order rate of 300,000 orders/second, the Order Generator (OG) emerged as the bottleneck. This evidence suggests that with enhancements to increasing the uniform rate of order generation the infrastructure can manage even higher throughput.
Throughout the stress test, we discovered the critical role of NUMA node configuration in maximizing performance and workload distribution. By strategically assigning processes and allocating resources to the appropriate NUMA nodes, we successfully minimized latency and contention, reducing memory access time across different nodes. This approach not only optimized inter-thread communication with significantly lower latency but also harnessed the benefits of L3 cache, ultimately enhancing the overall system performance and efficiency.
Our system demonstrated its ability to preserve low latency even at substantial volumes. Notably, the system could process up to 50,000 orders per second while maintaining a 99th percentile latency of 12.7 microseconds, even at a sustained one-hour load (Figure 3). This performance under pressure highlights the resilience, scalability, and efficiency of our trading system in high-demand scenarios.

Figure 3. Total system latency for one order stream at 50,000 orders/second
|
Date |
2023-06-30 |
|
Instance Type |
Virtual |
|
Network |
InfiniBand |
|
Msg Rate/pair |
50,000 orders/sec |
|
Avg Latency |
8.8μs |
|
Total msg rate |
50,000 orders/sec |
|
90th % |
9.6μs |
|
99th % |
12.7μs |
|
Max Latency |
1.564ms |
Table 3: Results for single order stream
Managing 'Noisy Neighbours'
In our line of work, we often encounter what we refer to as 'noisy neighbors,' which are unrelated processes that share the same physical host and have the potential to intermittently impact system performance. However, throughout our comprehensive testing phase on Azure's advanced network protocol, we observed no significant interference from such factors. It is worth noting that Azure also provides the option of using dedicated hosts, which could be a valuable choice for those looking to completely avoid this potential interference.
Conclusion
Our tests clearly demonstrated that hosting a low-latency trading system on Microsoft Azure is not only viable but can also deliver significant performance improvements when leveraging RDMA-enabled instances and advanced networking technology. The study we have performed should be used as confirmation of cloud capabilities by those weighing the cost and opportunity of a transition. Early adopters of cloud services have benefited from the advantages of improved resiliency, scalability, security, and flexibility. Those who choose today to build solutions in the cloud stand to achieve competitive performance as well.
As an experienced designer of low-latency trading platforms, BJSS offers digital architecture, roadmap, and delivery process advisory to banking clients in order to accelerate their adoption of cloud-native solutions and help them take advantage of the flexibility, scalability, and resiliency of cloud-hosted infrastructure.
We support our clients through every phase of their journey into trading in the cloud. From discovery to implementation and delivery of trading solutions, we aim to deliver a resilient trading solution that can scale elastically to meet market demands.
Find out more about our work with financial services organizations here.
Related posts



